XMLマスターポイントレッスン ~ プロフェッショナル(データベース)編 ~
第5回 XQueryのFLWOR式
データディレクトテクノロジーズ株式会社(現:日本プログレス株式会社)
山田敏彦 YAMADA, Toshihiko
今回はXML文書の構造を変換するXQueryの「FLWOR(フラワー)式」と、XQueryの強力な機能である「コンストラクタ」について解説します。FLWOR式はXQueryを代表する構文であり、本連載でも第2回で簡単に触れました。コンストラクタとFLWOR式を組み合わせることで検索結果を別のフォーマットのXML文書やHTML文書に変換できます。いずれもXQueryの根幹となる知識ですので100%理解できるようにしておきましょう。
FLWOR式によるXMLの検索
「FLWOR」とは、FLWOR式を構成する「for」「let」「where」「order by」「return」という5つのキーワードの頭文字の組み合わせから名付けられています。各キーワードは、それぞれfor句、let句、order by句、return句を導きます。全体で検索結果をシーケンスとして返します。
ところで、前回解説したXPathのPath式もXMLを検索し、その結果をシーケンスで返していました(注1)。FLWOR式とどこが違うのでしょうか。XMLの検索はPath式で充分ではないのでしょうか。
注1:「数値や論理値のようなアトミック値や、単一のノードを返す式もあったじゃないか」と思う方もいるかもしれません。連載第3回のシーケンス型の解説を思い出してください。アトミック値やノード値はその値のみを項目として持つ、長さ1のシーケンスと等値でしたね。すべてのアトミック値は同時にシーケンスでもあるのです。
Path式はFLWOR式よりも簡潔で直感的に分りやすい、という特徴がある一方、検索結果のシーケンスの順序を変更したり、検索結果を加工することができません。FLWOR式を使うことにより、このような処理を記述できるようになりますが、記述はPath式よりも冗長になります。実装によってはPath式のほうが処理が早いこともありますから、Path式で充分な場合はPath式、それ以上の機能が必要な場合はFLWOR式、というように状況に応じて両者を使い分けていくのが良いでしょう。FLWOR式の構文図を図1に示します。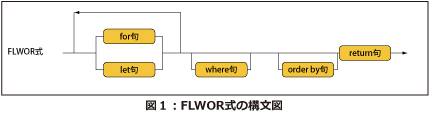
for、where、return句の使い方
それではいつものように、まずFLWOR式の例を見て行きましょう。前回使用したサンプルXML文書をLIST1に再掲します。
LIST1:サンプルXML文書(cust.xml)
<directory>
<customer id="10001">
<name gender="male">山下太郎</name>
<address type="office">東京都新宿区四谷2-4-1</address>
<phone type="mobile">090-xxxx-xxxx</phone>
<phone type="office">03-53xx-xxxx</phone>
</customer>
<customer id="10002">
<name gender="female">赤井道子</name>
<address type="home">東京都目黒区大岡山5-1-2</address>
<phone type="mobile">080-xxxx-xxxx</phone>
</customer>
<customer id="10003">
<name gender="male">大木伸城</name>
<address type="office">東京都大田区蒲田2-3-4</address>
<address type="home">東京都大田区蒲田5-6-7</address>
<phone type="office">03-xxxx-xxxx</phone>
<phone type="mobile">070-xxxx-xxxx</phone>
<phone type="home">03-xxxx-xxxx</phone>
</customer>
</directory>for $i in fn:doc("cust.xml")//name
where $i/@gender="male"
return $i
このFLWOR式にはfor句とwhere句、return句が使われています。詳しく見てみましょう。
for句の形式
for句は次のような形式になります。
"for" <変数> "in" <式>
for句は、<式>が返すシーケンスのすべての項目を処理する反復処理を行なうことを表わします。<変数>は反復処理を行なうたびにシーケンスの各項目にバインドされ、変数を宣言したfor句以降で評価すると、そのときバインドされているシーケンスの項目を参照できます(図2)。
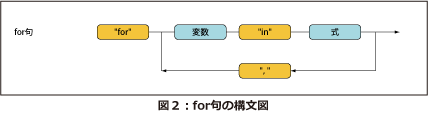
例に挙げたFLWOR式では、「$i」という変数がLISTのすべてのname要素にバインドされながら3回の反復処理が行なわれることになります。
where句の形式
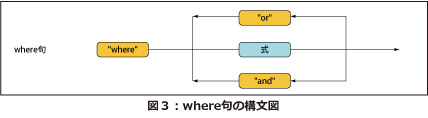
where句は次のような形式になります。
"where" <式>
<式>は論理値か、論理値として解釈される値(注2)を返す式でなければなりません。
注2:例えば、xs:numeric型の値は0であればfalse、それ以外はtrueとして解釈されます。詳細は前回のコラム 「論理値として解釈される値」 を参照してください。
通常はfor句で宣言した変数をテストする条件式を記述し、処理対象から除外する項目をフィルタする役目を果たします。条件式がfalseを返した場合、それ以降のorder by句やreturn句は評価されず、次の反復処理が行なわれます。例に挙げたFLWOR式では、$iにバインドされているname要素のgender属性が「male」であるかどうかをテストし、「male」でない項目をフィルタしています(図3)。
return句の形式
return句は次のような形式になります。
"return" <式>
(where句でフィルタされていなければ)反復処理1回ごとに<式>を評価します。評価した結果はすべての反復処理が完了した後、FLWOR式全体の返却値として1つのシーケンスに処理順にまとめられて返されます。
例に挙げたFLWOR式では、1回の反復処理ごとに$iを評価します。各反復処理時に$iにバインドされていたname要素が連結されたシーケンスがFLWOR式の結果として返されます。
全体をまとめると、この例では「cust.xmlのすべてのname要素のうち、gender属性がmaleであるようなものを検索してシーケンスとして返している」ことになります。
また、実行結果は次の2つのname要素を項目として持つシーケンスになります。
<name gender="male">山下太郎</name>
<name gender="male">大木伸城</name>
この程度の処理であれば、Path式を使ったほうが簡潔でしょう。同じ結果を得られるPath式の例を次に示します。このPath式については前回で詳細に解説しましたので、説明は省略します。
fn:doc("cust.xml")//customer/name[@gender="male"]
return句の構文図を図4に示します。

let、order by句の使い方
次に、Path式ではできない処理を行なうFLWOR式を見てみましょう。
まず、order by句で検索結果をソートする例です。
for $i in fn:doc("cust.xml")//name
where $i/@gender="male"
oreder by $i/../@id descending
return $i
このクエリを実行すると、検索結果が顧客IDの逆順にソートされ、次のような結果になります。
<name gender="male">大木伸城</name>
<name gender="male">山下太郎</name>
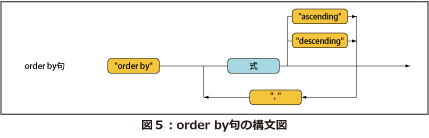
order by句の形式
order by句は、次のような形式になります。
"order by" <式> (descending)
<式>で指定された値により検索結果をソートします。descendingは降順にソートすることを指示するキーワードで、省略可能です。descendingを省略すると昇順にソートされます。
先ほどのFLWOR式の例では、$iがバインドされているname要素の親要素にあたるcustomer要素のid属性の降順にソートしています。
order by句の構文図を図5に示します。
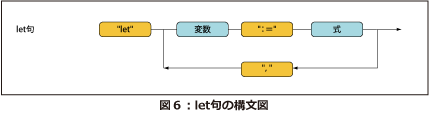
let句の形式
let句は、次のような形式になります。
"let" 変数 ":=" <式>
変数を宣言して<式>の評価結果をバインドします。バインドされた値は変数を宣言したlet句以降で参照可能です。
今度は、let句を先ほどのFLWOR式に追加してみましょう。
for $i in fn:doc("cust.xml")//name
let $phones := fn:count($i/../phone)
where $i/@gender="male"
order by $i/../@id descending
return ($i, $phones)
fn:count()関数はパラメータとして渡されたシーケンスの項目数をxs:integerの値で返します。パラメータは「$i/../phone」ですから、$iにバインドされているname要素の親要素であるcustomer要素の子要素であるphone要素がすべて含まれたシーケンスが指定されています。$iにバインドされているname要素の兄弟要素であるphone要素の数が返されるわけです。
つまり、大木伸城さんの場合は会社、携帯、自宅の3種類の電話番号が登録されており、山下太郎さんは会社と携帯の電話番号が登録されているので、fn:count()関数はそれぞれ3と2を返します。
結果は、次のようにノードとxs:integer値が混在したシーケンスになります。
<name gender="male">大木伸城</name>
3
<name gender="male">山下太郎</name>
2
let句の構文図を図6に示します。
コンストラクタを使用した文書変換
ここまでの例では、単に元の文書にあるノードをシーケンスにして返すだけでした。XQueryの「コンストラクタ」という機能とFLWOR式を組み合わせると、検索結果を利用して新しいXML文書を生成できます。
ここでは、FLWOR式とコンストラクタを組み合わせて、フォーマット変換を行なう例をいくつか見てみましょう。上記のFLWOR式にコンストラクタを組み合わせたクエリを次に示します。
<cust2>
{
for $i in fn:doc("cust.xml")//name
let $phones := fn:count($i/../phone)
where $i/@gender = "male"
order by $i/../@id descending
return
<cust>
{ element id {fn:string($i/../@id)} }
<name>{ $i/text() }</name>
<phones>{ $phones }</phones>
</cust>
}
</cust2>
for、let、where、order byの部分は先ほどと変わっていませんね。変化しているのは、全体が
<cust2>
{
……
}
</cust2>
で囲まれていること、return句の中身が変わっていることの2点です。よく見ると、return句の中にも「<cust>……</cust>」や「<name> {……} </name>」のようによく似た構造があります。
これらの「<xxxx> {……} </xxxx>」という記法については、すでに連載第2回で説明しています。覚えていますか。「ダイレクトコンストラクタ」です。ダイレクトコンストラクタは、XMLと同じ記法を使用します。つまり、「<cust2>……</cust2>」というダイレクトコンストラクタを記述すると、「<cust2>……</cust2>」という要素ノードが生成されます。では、「{……}」は何を意味していたでしょうか。「{」と「}」で囲まれた部分はXQueryの式として評価する必要があることを表わしていましたね。
例えば、
let $a := ( 1,2,3 )
return
<a>{$a}</a>
の結果は、次のようになります。
<a>1 2 3</a>
一方、
let $a := ( 1,2,3 )
return
<a> $a </a>
の結果は、次のようになります。
<a> $a </a>
ダイレクトコンストラクタでは、要素ノードのほかに処理命令ノード、コメントノードを生成できます。表1に、ダイレクトコンストラクタの書式と生成されるノード、使用例をまとめておきます。
表1:ダイレクトコンストラクタの種類
| ダイレクトコンストラクタの種類 | 生成されるノード | 使用例 | 備考 |
| "<" ノード名 属性名 "=" 属性値 ">" ・・・ "</" ノード名 ">" | 要素ノード、属性ノード | <name gender="male">大木隆</name> | 属性は0個以上記述可能 |
| "<!- -" 文字列 "- ->" | コメントノード | <- - コメントを生成します - -> | |
| "<?" 処理命令 "?>" | 処理命令ノード | <? FORMAT "INDENT" ?> |
もう1つのコンストラクタ
さて、もう一度return句の中をよく見てください。今までに説明していない構文があることに気付いたでしょうか。次の式です。
element id {fn:string($i/../@id)}
実は、これもコンストラクタです。「計算コンストラクタ(Computed Constructor)」と呼びます。計算コンストラクタは次の形式をとります(注3)。
注3:<ノード名>は、要素ノードや属性ノードのように名前のあるノードで指定します。テキストノードやドキュメントノードのように名前のないノードでは指定しません。
<ノード種別> <ノード名> "{" ノードの値 "}"<ノード種別>に入る計算コンストラクタのノード種別を表2にまとめておきます。
表2:計算コンテキスト(Computed Constructor)のノード種別一覧
| ノード種別 | 生成されるノード | 使用例 | 備考 |
| document | 文書ノード | document { <a> fn:doc("sample.xml")//b </a> } | フラグメントをドキュメントにする際に使用 |
| element | 要素ノード | element name { "大木隆" } | |
| attribute | 属性ノード | attribute birthDay { "06/20/80" } | |
| text | テキストノード | text { "generating a text node" } | |
| comment | コメントノード | comment { "This is comment" } | |
| processing-instruction | 処理命令ノード | processing-instruction { "GRAPHIC" }{ "SVG 1.0" } |
上記の例では、ノード種別が「element」、ノード名が「id」ですから、idという名前の要素ノードが生成されます。fn:string()はパラメータをxs:stringに変換した値を返します。パラメータに指定されているのは$iがバインドされているname要素の親要素であるcustomer要素のid属性の値です。ですから、全体で「customer要素のid属性の値を持つidという名前の要素ノードを生成する」という意味になります。
つまり、もとのXMLではcustomer要素の属性であったidをidという新しい要素に変換していることになります。
FLWOR式とコンストラクタを組み合わせた使用法
さて、これで先ほどのFLWOR式にコンストラクタを組み合わせたクエリを読む準備ができました。クエリの外側から順を追って見ていきましょう。
(1)ダイレクトコンストラクタにより「cust2」という要素ノードが生成される
(2)FLWOR式によりcust2ノードには顧客IDの逆順にcustという子ノードが生成されるが、where句の指定により女性顧客はフィルタされる
(3)custノードは顧客IDを持つid、顧客名を持つname、登録されている電話番号の数を持つphonesの各要素ノードを子ノードとして持つ
実行結果は次のようになります。
<cust2>
<cust>
<id>10003</id>
<name>大木伸城</name>
<phones>3</phones>
</cust>
<cust>
<id>10001</id>
<name>山下太郎</name>
<phones>2</phones>
</cust>
</cust2>
このように、コンストラクタとFLWOR式を組み合わせることで、検索結果を整形できます。この機能は強力です。例えば、LIST2を見てください。検索結果をHTMLに変換するクエリです。これだけでWebベースのアプリケーションの1つの機能がほぼ完成してしまいます。
LIST2:検索結果をHTMLに変換するクエリ
<html>
<table>
<tr><td>顧客番号</td><td>顧客名</td><td>登録電番数</td></tr>
{
for $i in fn:doc("cust.xml")//name
let $phones := fn:count($i/../phone)
where $i/@gender = "male"
order by $i/../@id descending
return
<tr>
{ element td {fn:string($i/../@id)} }
<td>{ $i/text() }</td>
<td>{ $phones }</td>
</tr>
}
</table>
<html>LIST3:LIST2の実行結果
<html>
<table>
<tr><td>顧客番号</td><td>顧客名</td><td>登録電番数</td></tr>
<tr><td>10003</td><td>大木伸城</td><td>3</td></tr>
<tr><td>10001</td><td>山下太郎</td><td>2</td></tr>
</table>
<html>現時点ではこれといった原則が確立しているわけではないので、ケースバイケースで考えるしかありません。筆者の場合はデータソースを検索するのが主眼となる処理、特にデータソースがCSVやRDBの場合はXQuery、フォーマット変換が主眼となる処理はXSLTといった使い分けをしていますが、その基準は多分に感覚的です。今後、経験を蓄積するにつれて筆者なりの指針のようなものがまとまってくるのではないかと思っています。
今月の確認問題
ここまで、XQueryのFLWOR式を解説してきました。ここで、今回解説した内容について、しっかりと理解できているかどうかを確認問題でチェックしてみましょう。
問題
次の[sample.xml]に対して[XQuery]による問い合わせを実行した結果として、正しいものを選択してください。
ただし、XQueryプロセッサはfn:doc関数で[sample.xml]を正常に読み込むことができるものとします。
また、結果のXML宣言の有無やインデントは考慮しません。
[ sample.xml ]
<BOOKS>
<book id="B001" stock="10"/>
<book id="B002" stock="8"/>
<book id="B004" stock="20"/>
</BOOKS>[ XQuery ]
<result>{
for $book in fn:doc("sample.xml")//book
let $stock := $book/@stock
where $stock < 20
order by $stock
return $book
}</result><result>
<book id="B002" stock="8"/>
<book id="B001" stock="10"/>
</result><result>
<book id="B001" stock="10"/>
<book id="B002" stock="8"/>
</result><result>
<book id="B001" stock="10"/>
<book id="B002" stock="8"/>
<book id="B004" stock="20"/>
</result><result>
<book id="B002" stock="8"/>
<book id="B001" stock="10"/>
<book id="B004" stock="20"/>
</result>解説
設問のクエリは、各々のbook要素について(for句)、stock属性値を$stock変数にバインドし(let句)、$stock変数の値でbook要素をフィルタリングし(where句)、$stock変数の値でタプル(この場合は各々のbook要素)を並べ替えた上で(order by句)、最後にbook要素を返します(return句)。where句でbook要素がフィルタリングされますので、CとDは誤りです。
ここで、order by句で昇順/降順の指定が省略されている場合や、並べ替え時に評価される値(この場合は$stock変数の値)が型指定されていない場合のデフォルトの振る舞いを確認しておく必要があります。
order by句で「ascending」または「descending」の記述が省略されている場合は、タプルは昇順(ascending)で並べ替えられます。また、並べ替え対象の値が型指定されていない場合は値を文字列として評価し、文字列はデフォルトではユニコードのコードポイント順で並べ替えられます。したがって設問の解答はBになります。
このとき、order by句の$stock変数を整数として評価する場合は明示的にキャストする必要があり、order by句を「order by $stock cast as xs:int」と記述します。この場合の問い合わせ結果はAとなります。
* * *
今回は、FLWOR式について詳細に解説しました。また、XQueryのもう1つの強力な機能、コンストラクタとFLWOR式を組み合わせることで検索結果を別のフォーマットのXML文書やHTML文書に変換できることを学びました。以下に、今回のポイントを一覧にしておきます。
次回は、FLWOR式の応用編として「JOIN」をテーマに解説したいと思います。お楽しみに!
山田敏彦 (やまだとしひこ)
慶應義塾大学理工学部卒、日立ソフト、サイベースなどを経て、2003年より現職。ビールが美味しい季節になってきましたね。しかし、Tシャツを着るとお腹が「ビールを控えろ!」と主張しているようで気が引けます。真面目にビリー軍曹に鍛えてもらおうかと思う今日この頃です……。
<掲載> P.200-205 DB Magazine 2007 September
XMLマスターポイントレッスン ~ プロフェッショナル(データベース)編 ~ 記事一覧へ戻る
![]()
