XMLマスターポイントレッスン ~ プロフェッショナル(データベース)編 ~
第4回 XPathの主要な式と演算子
データディレクトテクノロジーズ株式会社(現:日本プログレス株式会社)
山田敏彦 YAMADA, Toshihiko
今回は、XPathによるパスの指定方法を中心に、XPath 2.0の主要な式と演算子について解説します。XQueryでは、対象となるXML文書のどの部分を検索対象にするかをXPathを使用して指定します。XPathを使いこなせるようにしておくと、XQueryでコードを組む際にずいぶん楽できるようになりますので、しっかりマスターしてください。また「すでにある程度知っている」という人も、ここで復習しておきましょう。
XQueryとXPathの関係
XPathは、XML文書のどの部分を検索対象にするかを指定するために使用します。SQLに無理矢理なぞらえると、SELECT文のカラム名指定にあたります。ところが、XML文書は木構造を持ち、要素名の重複も許されますから、単に要素名を列記しただけでは対象の要素を特定できません。
そこで、現在着目している要素(コンテキストノード。後述)から対象の要素まで、どのように木を辿っていくかを指定して対象要素を特定します。例えば、「ルート要素の子要素であるCustの属性であるid」という具合です。ちょうどWindowsやLinuxで特定のファイルを指定するときにカレントディレクトリからどのようにフォルダを辿っていけば目的のファイルに行き着けるかを指定するのと同じです。
XPathで記述する木の辿り方も、WindowsやLinuxと同じように「パス」と呼びます。パスの辿り方を指定する記法が「XPath」というわけです。ですから、XPathをうまく使いこなすことが良いクエリを書くためのポイントの1つになります。
XPathを使用したパスの指定方法(パス式)
まず、XPathによるパスの指定方法を見てみましょう。「XPath 1.0には詳しいよ」という方は、復習のつもりで読んでください。
以下に、LISTのXML文書を検索するXPathの例を示します。このような式を「パス式」と呼びます(LISTのXML文書は「cust.xml」というファイルに保存されているとします)。
LIST:サンプルXML文書(cust.xml)
<directory>
<customer id="10001">
<name gender="male">山下太郎</name>
<address type="office">東京都新宿区四谷2-4-1</address>
<phone type="mobile">090-xxxx-xxxx</phone>
<phone type="office">03-53xx-xxxx</phone>
</customer>
<customer id="10002">
<name gender="female">赤井道子</name>
<address type="home">東京都目黒区大岡山5-1-2</address>
<phone type="mobile">080-xxxx-xxxx</phone>
</customer>
<customer id="10003">
<name gender="male">大木伸城</name>
<address type="office">東京都大田区蒲田2-3-4</address>
<address type="home">東京都大田区蒲田5-6-7</address>
<phone type="office">03-xxxx-xxxx</phone>
<phone type="mobile">070-xxxx-xxxx</phone>
<phone type="home">03-xxxx-xxxx</phone>
</customer>
</directory>LISTのXML文書(cust.xml)を検索するXPathの例
fn:doc("cust.xml")/descendant::customer/
child::name[attribute::gender="male"]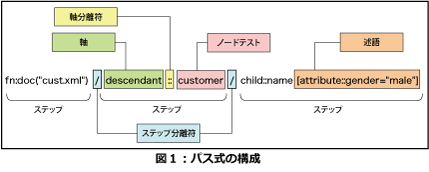
次のステップを評価する際には、コンテキストノードはcustomerノードに移っています。「child」はコンテキストノードの直接の子ノードを表わす軸です。ですから、child::nameはcustomerノードの直接の子ノードで「name」という名前のノードになります。attributeはコンテキストノードの属性ノードを意味する軸です。ですから、attribute::genderでgenderという名前の属性ノードを意味します。[attribute::gender="male"]は絞り込み条件を指定する述語ですから、全体で「genderという属性ノードの値が"male"である」という絞り込み条件を示します。
したがって、この式全体で「ドキュメントに含まれているすべてのcustomerノードの直接の子ノードであるnameノードのうち、gender属性の値が"male"であるようなノード」を表わすことになります。実行結果は次のようになります。
<name gender="male">山下太郎</name>
<name gender="male">大木伸城</name>
軸(Axis)
軸はchildやdescendantなど11種類が定義されています。ステップごとに軸を指定するのは少し煩雑なので、XPathでは軸の略記法も定義されています。表1に主な軸とその略記法を挙げておきます。
略記法を使って書き直すと、先のXPath式は次のようになります。
fn:doc("cust.xml")//customer/
name[@gender="male"]
表1:主な軸とその略記法
| 軸 | 略記法 | 意味 | 使用例 |
| attribute | 「attribute::<属性名>」を「@<属性名>」 | コンテキストノードに関連付けられた属性ノード | x/attribute::y (略記法ではx/@y) |
| child | なし | コンテキストノードの直接の子ノード | x/child::y (略記法ではx/y) |
| parent | 「parent::node()」を「..」 | コンテキストノードの親ノード | x/parent::node()/y (略記法ではx/../y) |
| self | 「self::node()」を「.」 | コンテキストノード自身 | x/self::node() (略記法ではx/.) |
| descendant | なし | コンテキストノードのすべての子孫ノード | x/descendant::y |
| descendant-or-self | 「descendant-or-self::node()」を「//」 | コンテキストノード自身とすべての子孫ノード | x/descendant-or-self::node()/y (略記法ではx//y) |
ノードテスト
例では、ノードの名前をノードテストに使用しています。これは「ノード名テスト」と呼ばれ、指定されたノード名を持つノードにマッチします。ノード名テストではワイルドカード文字(「*」)も使用できます。例えば、「/customer/*」というパス式はcustomerのすべての子ノードを返します。
ノードテストには、ノード名テストのほかに「ノード種別テスト」があります。これは指定された種別のノードとマッチします。XDMには7種類のノードが定義されていましたね。表2に主なノード種別テストをまとめておきます。
表1:主なノード種別テスト
| ノード種別テスト | 意味 | 使用例 |
| document-node() | ドキュメントノードにマッチする | fn:doc("fugahoge")/self::document-node() |
| element() | 任意の要素ノードにマッチする | x/element() |
| attribute() | 任意の属性ノードにマッチする | x/attribute() |
| node() | 任意のノードにマッチする | x/node() |
| text() | 任意のテキストノードにマッチする | x/text() |
| comment() | 任意のコメントノードにマッチする | x/comment() |
| processing-instruction() | 任意の処理命令ノードにマッチする | fn:doc("fugahoge")//processing-instruction() |
述部
軸とノードテストで指定された対象ノードを絞り込むために指定するのが述語です。先ほどの例の[attribute::gender="male"]の部分です。
「[ ]」で囲まれた部分を「述語式」と言います。述語式には整数を返す式や論理値を返す式を指定します。先ほどの例では、attribute::gender="male"という比較式(比較式については後述します)を指定して男性だけを抽出しました。
もう1つ、比較式を述語式に使用する例を見てみましょう。
fn:doc("cust.xml")//customer[fn:position()=1]
このパス式は、次のように1番目のcustomer要素を返します。<customer id="10001">
<name gender="male">山下太郎</name>
<address type="office">東京都新宿区四谷2-4-1</address>
<phone type="mobile">090-xxxx-xxxx</phone>
<phone type="office">03-53xx-xxxx</phone>
</customer>「fn:position()=1」という比較式がtrueになるのは1番目のcustomerノードがコンテキストノードになったときだけですから、山下太郎さん以外の情報はフィルタされて赤井道子さん、大木伸城さんの情報は棄てられてしまったわけです。
また、この指定方法は次のように略記できます。
fn:doc("cust.xml")//customer[1]
このように述語式として整数式を記述した場合は、フォーカスのうち整数式の評価結果と等しい順序を持つ項目のみを取り出す、という絞り込み条件になります。絶対パスと相対パス
WindowsやLinuxのファイルパスに絶対パスと相対パスがあるのと同様に、XPathにも絶対パスと相対パスがあります。絶対パスは「/」か「//」から始まるパスで、コンテキストノードが属しているノード木のルートノードを始点とするパスであることを意味しています。ファイルパスの絶対パスがルートディレクトリから始まるのと同じですね。
例えば、「/directory/customer/name[@gender="female"]」が絶対パス指定、「customer/name[gender="female"]」が相対パス指定です。
相対パスはコンテキストノードを始点とするパス指定です。相対ファイルパスがワーキングディレクトリから始まる指定方法なのと同じです。
絶対パスと相対パス
XPathの式はパス式だけではありません。ほかにも数値式、論理式、シーケンス式、比較式などがあります。そこで、以降ではXPath 2.0の主な式と演算子を簡単に見ていきましょう。
数値式
「数値式」は、xs:decimal、xs:integer、xs:float、xs:doubleを被演算子として、数値演算子を使用して構成されます。表3に数値演算子の一覧を、次に数値式の例を示します。
5 div 2 → 2.5を返す
5 idiv 2 → 2を返す
5 mod 2 → 1を返す
表3:数値演算子
| 演算子 | 意味 |
| + | 第1被演算子と第2被演算子の和を返す |
| - | 第1被演算子と第2被演算子の差を返す |
| * | 第1被演算子と第2被演算子の積を返す |
| div | 第1被演算子を第2被演算子で除した結果を返す |
| idiv | 第1被演算子を第2被演算子で除した結果の整数部を返す |
| mod | 第1被演算子を第2被演算子で除した剰余を返す |
| + (単項演算子) | 被演算子の正負を保持する |
| - (単項演算子) | 被演算子の正負を反転する |
論理式
「論理式」は、xs:booleanやシーケンス、アトミック値を被演算子として、論理演算子を使用して構成されます(コラム 「論理値として解釈される値」 を参照)。また、比較式を論理演算子で結合したものも論理式になります。表4に論理演算子を、次に論理式の例を示します。
(1 eq 1) and (2 ne 3) → trueを返す
($a = "x" ) or ( 0 ne 3) → $aの値に関わらずtrueを返す
表4:論理演算子
| 演算子 | 意味 |
| or | 第1被演算子と第2被演算子の論理和を返す |
| and | 第1被演算子と第2被演算子の論理積を返す |
シーケンス式
「シーケンス式」は、シーケンスを組み立てたり、フィルタしたり、組み合わせたりしてシーケンスを返す式です。
シーケンスの組み立てには「,」(カンマ演算子)とto演算子を使用します。カンマ演算子を使用したシーケンス式の例を次に示します。
(1, 2, 3, 4, 5 )→ 1、2、3、4、5というアトミック値を項目として持つシーケンスを返す
もう、おなじみの式ですね。特に説明も必要ないかと思います。一方、to演算子を使用したシーケンス式は次のようになります。
1 to 5 → 1、2、3、4、5というアトミック値を項目として持つシーケンスを返す
直感的に分かりやすく簡潔ですね。カンマ演算子とto演算子を組み合わせることもできます。
(1, 2, 5 to 10)→ 1、2、5、6、7、8、9、10というアトミック値を項目として持つシーケンスを返す
フィルタ式
「フィルタ式」は、シーケンスやノード値に述語を続けて記述し、シーケンスやノードの絞り込みを行なう式です。
( 1 to 100 )[. mod 5 eq 0]
→ 1以上100以下の5の倍数からなるシーケンスを返す
シーケンスを組み合わせて新しいシーケンスを作るには、union演算子、intersect演算子、except演算子を使用します。
union演算子は2つのシーケンスの持つすべての項目からなるシーケンスを返し、intersect演算子は2つのシーケンスのどちらにも存在する項目からなるシーケンスを返します。except演算子は第一被演算子には存在するが、第二被演算子には存在しない項目からなるシーケンスを返します。図2にunion、intersect、except演算子の関係を示します。
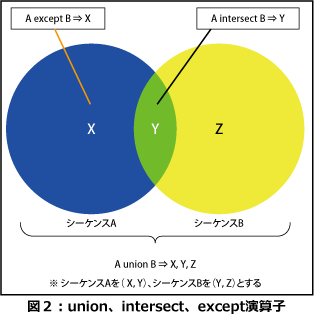
( X,Y ) union ( Y,Z ) → X、Y、Zを項目として持つシーケンスを返す
( X,Y ) intersect ( Y,Z ) → Yを項目として持つシーケンスを返す
( X,Y ) except ( Y,Z ) → Xを項目として持つシーケンスを返す
( X,Y ) except ( X,Y ) → 空シーケンスを返す
union、intersect、exceptの各演算子は被演算子としてノード値のみからなるシーケンスをとり、重複したノード(注)は結果として生成されるシーケンスに含めません。できあがったシーケンスは文書順に基づいた順序を持ちます。
注:たとえ同じ型、同じ値を持っていたとしても、異なるノードは識別されることを思い出してください。そのようなノードはここで言う重複には該当しません。
シーケンス式で使用する演算子を表5にまとめておきます。表5:シーケンス式で使用する演算子
| 演算子 | 意味 |
| , | 被演算子を評価、結合してシーケンスを作成する |
| to | 第1被演算子から第2被演算子までの連続した整数からなるシーケンスを作成する |
| union | ノードのみから構成される2つのシーケンスのすべての項目からなるシーケンスを作成 |
| intersect | ノードのみから構成される2つのシーケンスが共通して持つ項目のみからなるシーケンスを作成 |
| except | ノードのみから構成される2つのシーケンスを被演算子として、第1被演算子のみに存在する項目からなるシーケンスを作成 |
比較式
「比較式」は、値を比較して論理値を返す式です。XPath 2.0では比較する被演算子に応じて値比較演算子と一般比較演算子、ノード比較演算子の3種類の演算子を用意しています。値比較演算子を表6にまとめました。
表6:値比較演算子
| 演算子 | 意味 |
| eq | 第1被演算子と第2被演算子が等しければtrueを返す |
| ne | 第1被演算子と第2被演算子が等しくなければtrueを返す |
| lt | 第1被演算子が第2被演算子よりも小さければtrueを返す |
| le | 第1被演算子が第2被演算子よりも小さいか、等しければtrueを返す |
| gt | 第1被演算子が第2被演算子よりも大きければtrueを返す |
| ge | 第1被演算子が第2被演算子よりも大きいか、等しければtrueを返す |
//bookTitle[pages lt 100]
これは、述語に値比較演算子を使用した例です。与えられたXMLドキュメントに存在するすべてのbookTitleノードのうち、直接の子ノードであるpagesノードの値が100より小さいノードを抽出するパス式です。
一般比較演算子は、アトミック値だけではなくシーケンスの比較もできますが、その動作はトリッキーです。例を挙げて説明しましょう。
1 = 1 → trueを返す
右辺、左辺ともにアトミック値であれば一般比較演算子と値比較演算子の振る舞いに違いはありません。
(1, 0)= 1 → trueを返す
一方がシーケンス、他方がアトミック値になると、シーケンスの各項目とアトミック値の組み合わせをすべて評価し、1つでも指定された条件を満たせばtrueを返します。この例では「1=1」、「0=1」の2つの組み合わせについて評価します。「1=1」が真なのでtrueが返されます。
(1,0)=(1,0) → trueを返す
両辺がシーケンスになると、各シーケンスの項目すべての組み合わせについて比較を行ないます。やはり、1つの組み合わせでも指定された条件を満たせばtrueを返します。
この例では、「1=1」、「1=0」、「0=1」、「0=0」の各組み合わせを評価します。「1=1」と「0=0」が真なのでtrueが返ります。
(1,2)=(1,5) → trueを返す
「1=1」の組み合わせが存在するのでtrueが返ります。
(1,2)!=(1,5) → trueを返す
「1!=5」、「2!=1」のように等しくない組み合わせが存在するのでtrueが返ります。大小比較も同じように行なわれるので、(1,2)と(1,5)はすべての一般比較演算でtrueが返ることになります。表7に一般比較演算子をまとめておきます。
表7:一般比較演算子
| 演算子 | 意味 |
| = | 第1被演算子と第2被演算子が等しければtrueを返す |
| != | 第1被演算子と第2被演算子が等しくなければtrueを返す |
| < | 第1被演算子が第2被演算子よりも小さければtrueを返す |
| <= | 第1被演算子が第2被演算子よりも小さいか、等しければtrueを返す |
| > | 第1被演算子が第2被演算子よりも大きければtrueを返す |
| >= | 第1被演算子が第2被演算子よりも大きいか、等しければtrueを返す |
let $cust := fn:doc("cust.xml")
return
$cust//customer[@id = "10002"] is
$cust//customer[2]
is演算子の左辺はid属性の値が「10002」になるcustomerノードを指定していますから、赤井道子さんのノードが該当します。一方、右辺は2番目のcustomerノードを指定していますから、これも赤井道子さんのノードです。結果はtrueが返ります。表8にノード比較演算子をまとめておきます。
表8:ノード比較演算子
| 演算子 | 意味 |
| is | 第1被演算子と第2被演算子が同じノードならtrueを返す |
| << | 第1被演算子の文書順が第2被演算子よりも若くなければtrueを返す |
| >> | 第1被演算子の文書順が第2被演算子よりも若ければtrueを返す |
今月の確認問題
ここまで、XPathによるパスの指定方法を中心にXPathの主要な式と演算子を解説してきました。ここで、今回解説した内容について、しっかりと理解できているかどうかを確認問題でチェックしてみましょう。
問題1
次のXQueryによる問い合わせを実行した結果として、正しいものを選択してください。
結果のXML宣言の有無やインデントを考慮しません。
[ XQuery ]
let $A := (1,2), $B := (2,3)
return
<result>
<equal>{$A = $B}</equal>
<notequal>{$A != $B}</notequal>
</result><result>
<equal>true</equal>
<notequal>true</notequal>
</result><result>
<equal>true</equal>
<notequal>false</notequal>
</result><result>
<equal>false</equal>
<notequal>true</notequal>
</result><result>
<equal>false</equal>
<notequal>false</notequal>
</result>解説
「=」や「!=」によるシーケンスの比較は、個々の項目同士を比較し条件が成立するケースが1つ以上含まれている場合に結果がtrueになります。すなわち、「$A = $B」の場合、「1 = 2」、「1 = 3」、「2 = 2」、「2 = 3」による比較のうち、条件が成立するケースが1つ含まれていますので、結果はtrueです。
同様に、「$A != $B」の場合も比較条件が成立するケースが3つ含まれていますので結果はtrueです。よって、正解はAです。
問題2
次のsample.xmlに対して、XQuery1による問い合わせを実行した結果、およびXQuery2による問い合わせを実行した結果として、正しいものをそれぞれ選択してください。
ただし、XQueryプロセッサはfn:doc関数でsample.xmlを正常に読み込むことができるものとします。結果のテキスト宣言の有無やインデントを考慮しません。
[ sample.xml ]
<sample>
<a>Dog</a>
<b>Cat</b>
</sample>[ XQuery1 ]
fn:doc("sample.xml")/sample/a, fn:doc("sample.xml")/sample/b[ XQuery2 ]
let $sample := fn:doc("sample.xml")
return
$sample/sample/a, $sample/sample/b- Dog, Cat
- <a>Dog</a>, <b>Cat</b>
- <a>Dog</a>
<b>Cat</b> - 問い合わせ実行時にエラーになる
解説
XQueryによるクエリ本文ではカンマ(,)の優先度は低く、そのためトップレベルのカンマには注意する必要があります。
XQuery1の場合、カンマの優先度が低いため、まずカンマの手前の式「fn:doc("sample.xml")/sample/a」が評価され、次にカンマの後ろの式「fn:doc("sample.xml")/sample/b」が評価され、最後にその結果を連結したものがクエリ結果になります。したがって、XQuery1の問い合わせ結果はCとなります。
同様に、XQuery2の場合もカンマの手前までが1つの式として評価され、そしてカンマの後ろが式「$sample/sample/b」として評価されます。このとき後者の式「$sample/sample/b」だけに注目した場合、そこに変数$sampleの宣言がありませんので、この点でエラーになります。こちらの正解はDです。
ここで、XQuery2についてエラーにならない記述に変更するには、returnの後ろに括弧を付けて「($sample/sample/a, $sample/sample/b)」と記述します。この場合の問い合わせ結果はCとなります。
* * *
今回はXPath 2.0について少し突っ込んだ解説を行ないました。内容が盛りだくさんになってしまいましたが、XPathを使いこなせるようになれば、XQueryでコードを組むのがずいぶん楽になると思います。よく復習しておいてください。
次に、今回解説した項目をまとめておきます。
次回は、いよいよXQueryのFLWOR(for、let、where、order、return)式について解説します。
山田敏彦 (やまだとしひこ)
慶應義塾大学理工学部卒、日立ソフト、サイベースなどを経て、2003年より現職。この原稿を執筆している4〜5月の天気の良い週末の午後は新宿御苑で過ごしています。風が涼しく、爽やかで気持ちよく過ごせます。お奨めですよ!
<掲載> P.205-211 DB Magazine 2007 August
XMLマスターポイントレッスン ~ プロフェッショナル(データベース)編 ~ 記事一覧へ戻る
![]()
